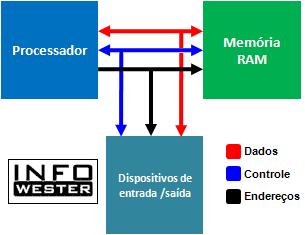
Introdução
No que se refere ao hardware dos computadores, entendemos como memória os dispositivos que armazenam os dados com os quais o processador trabalha. Há, essencialmente, duas categorias de memórias:
ROM (
Read-Only Memory), que permite apenas a leitura dos dados e não perde informação na ausência de energia; e
RAM (
Random-Access Memory), que permite ao processador tanto a leitura quanto a gravação de dados e perde informação quando não há alimentação elétrica. Neste artigo, o InfoWester apresenta os principais tipos de memórias ROM e RAM, assim como mostra as características mais importantes desses dispositivos, como frequência, latência, encapsulamento, tecnologia, entre outros.
Memória ROM
As
memórias ROM (
Read-Only Memory - Memória Somente de Leitura) recebem esse nome porque os dados são gravados nelas apenas uma vez. Depois disso, essas informações não podem ser apagadas ou alteradas, apenas lidas pelo computador, exceto por meio de procedimentos especiais. Outra característica das memórias ROM é que elas são do tipo
não voláteis, isto é, os dados gravados não são perdidos na ausência de energia elétrica ao dispositivo. Eis os principais tipos de memória ROM:
-
PROM (
Programmable Read-Only Memory): esse é um dos primeiros tipos de memória ROM. A gravação de dados neste tipo é realizada por meio de aparelhos que trabalham através de uma reação física com elementos elétricos. Uma vez que isso ocorre, os dados gravados na memória PROM não podem ser apagados ou alterados;
-
EPROM (
Erasable Programmable Read-Only Memory): as memórias EPROM têm como principal característica a capacidade de permitir que dados sejam regravados no dispositivo. Isso é feito com o auxílio de um componente que emite luz ultravioleta. Nesse processo, os dados gravados precisam ser apagados por completo. Somente depois disso é que uma nova gravação pode ser feita;
-
EEPROM (
Electrically-Erasable Programmable Read-Only Memory): este tipo de memória ROM também permite a regravação de dados, no entanto, ao contrário do que acontece com as memórias EPROM, os processos para apagar e gravar dados são feitos eletricamente, fazendo com que não seja necessário mover o dispositivo de seu lugar para um aparelho especial para que a regravação ocorra;
-
EAROM (
Electrically-Alterable Programmable Read-Only Memory): as memórias EAROM podem ser vistas como um tipo de EEPROM. Sua principal característica é o fato de que os dados gravados podem ser alterados aos poucos, razão pela qual esse tipo é geralmente utilizado em aplicações que exigem apenas reescrita parcial de informações;
-
Flash: as memórias Flash também podem ser vistas como um tipo de EEPROM, no entanto, o processo de gravação (e regravação) é muito mais rápido. Além disso, memórias Flash são mais duráveis e podem guardar um volume elevado de dados. É possível saber mais sobre esse tipo de memória no artigo
Cartões de memória Flash, publicado aqui no InfoWester;
-
CD-ROM,
DVD-ROM e afins: essa é uma categoria de discos ópticos onde os dados são gravados apenas uma vez, seja de fábrica, como os CDs de músicas, ou com dados próprios do usuário, quando o próprio efetua a gravação. Há também uma categoria que pode ser comparada ao tipo EEPROM, pois permite a regravação de dados: CD-RW e DVD-RW e afins.
Memória RAM
As
memórias RAM (
Random-Access Memory - Memória de Acesso Aleatório) constituem uma das partes mais importantes dos computadores, pois são nelas que o processador armazena os dados com os quais está lidando. Esse tipo de memória tem um processo de gravação de dados extremamente rápido, se comparado aos vários tipos de memória ROM. No entanto, as informações gravadas se perdem quando não há mais energia elétrica, isto é, quando o computador é desligado, sendo, portanto, um tipo de memória
volátil.
Há dois tipos de tecnologia de memória RAM que são muitos utilizados: estático e dinâmico, isto é, SRAM e DRAM, respectivamente. Há também um tipo mais recente chamado de MRAM. Eis uma breve explicação de cada tipo:
-
SRAM (
Static Random-Access Memory - RAM Estática): esse tipo é muito mais rápido que as memórias DRAM, porém armazena menos dados e possui preço elevado se considerarmos o custo por megabyte. Memórias SRAM costumam ser utilizadas como cache (saiba mais sobre cache
neste artigo sobre processadores);
-
DRAM (
Dynamic Random-Access Memory - RAM Dinâmica): memórias desse tipo possuem capacidade alta, isto é, podem comportar grandes quantidades de dados. No entanto, o acesso a essas informações costuma ser mais lento que o acesso às memórias estáticas. Esse tipo também costuma ter preço bem menor quando comparado ao tipo estático;
-
MRAM (
Magnetoresistive Random-Access Memory - RAM Magneto-resistiva): a memória MRAM vem sendo estudada há tempos, mas somente nos últimos anos é que as primeiras unidades surgiram. Trata-se de um tipo de memória até certo ponto semelhante à DRAM, mas que utiliza células magnéticas. Graças a isso, essas memórias consomem menor quantidade de energia, são mais rápidas e armazenam dados por um longo tempo, mesmo na ausência de energia elétrica. O problema das memórias MRAM é que elas armazenam pouca quantidade de dados e são muito caras, portanto, pouco provavelmente serão adotadas em larga escala.
Aspectos do funcionamento das memórias RAM
As memórias DRAM são formadas por chips que contém uma quantidade elevadíssima de capacitores e transistores. Basicamente, um capacitor e um transistor, juntos, formam uma
célula de memória. O primeiro tem a função de armazenar corrente elétrica por um certo tempo, enquanto que o segundo controla a passagem dessa corrente.
Se o capacitor estiver armazenamento corrente, tem-se um bit 1. Se não estiver, tem-se um bit 0. O problema é que a informação é mantida por um curto de período de tempo e, para que não haja perda de dados da memória, um componente do controlador de memória é responsável pela função de
refresh (ou refrescamento), que consiste em regravar o conteúdo da célula de tempos em tempos. Note que esse processo é realizado milhares de vezes por segundo.
O refresh é uma solução, porém acompanhada de "feitos colaterais": esse processo aumenta o consumo de energia e, por consequência, aumenta o calor gerado. Além disso, a velocidade de acesso à memória acaba sendo reduzida.
A memória SRAM, por sua vez, é bastante diferente da DRAM e o principal motivo para isso é o fato de que utiliza seis transistores (ou quatro transistores e dois resistores) para formar uma célula de memória. Na verdade, dois transistores ficam responsáveis pela tarefa de controle, enquanto que os demais ficam responsáveis pelo armazenamento elétrico, isto é, pela formação do bit. A
vantagem desse esquema é que o refresh acaba não sendo necessário, fazendo com que a memória SRAM seja mais rápida e consuma menos energia. Por outro lado, como sua fabricação é mais complexa e requer mais componentes, o seu custo acaba sendo extremamente elevado, encarecendo por demais a construção de um computador baseado somente nesse tipo. É por isso que sua utilização mais comum é como cache, pois para isso são necessárias pequenas quantidades de memória.
Como as memórias DRAM são mais comuns, eles serão o foco deste texto a partir deste ponto.
CAS e RAS
O processador armazena na memória RAM as informações com os quais trabalha, portanto, a todo momento, operações de gravação, eliminação e acesso aos dados são realizadas. Esse trabalho todo é possível graças ao trabalho de um circuito já citado chamado
controlador de memória.
Para facilitar a realização dessas operações, as células de memória são organizadas em uma espécie de matriz, ou seja, são orientadas em um esquema que lembra linhas e colunas. O cruzamento de uma certa linha (também chamada de
wordline), com uma determinada coluna (também chamada de
bitline) forma o que conhecemos como endereço de memória. Assim, para acessar o endereço de uma posição na memória, o controlador obtém o seu valor de coluna, ou seja, o valor
RAS (
Row Address Strobe) e o seu valor de linha, ou seja, o valor
CAS (
Column Address Strobe).
Temporização e latência das memórias
Os parâmetros de temporização e latência indicam quanto tempo o controlador de memória gasta com as operações de leitura e escrita. Em geral, quanto menor esse valores, mais rápidas são as operações.
Para que você possa entender, tomemos como exemplo um módulo de memória que informa os seguintes valores em relação à latência: 5-4-4-15-1T. Esse valor está escrito nesta forma:
tCL-tRCD-tRP-tRAS-CR. Vejamos o que cada um desses parâmetros significa:
-
tCL (
CAS Latency): quando uma operação de leitura de memória é iniciada, sinais são acionados para ativar as linhas (RAS) e as colunas (RAS) correspondentes, determinar se a operação é de leitura ou escrita (
CS -
Chip Select) e assim por diante. O parâmetro CAS Latency indica, em ciclos de clock (saiba mais sobre clock
nesta matéria sobre processadores), qual o período que há entre o envio do sinal CAS e a disponibilização dos respectivos dados. Em outras palavras, é o intervalo existente entre a requisição de um dado pelo processador e a entrega deste pela memória. Assim, no caso do nosso exemplo, esse valor é de 5 ciclos de clock;
-
tRCD (
RAS to CAS Delay): esse parâmetro indica, também em ciclos de clock, o intervalo que há entre a ativação da linha e da coluna de um determinado dado. No exemplo acima, esse valor corresponde a 4;
-
tRP (
RAS Precharge): intervalo em clocks que informa o tempo gasto entre desativar o acesso a uma linha e ativar o acesso a outra. Em nosso exemplo, esse valor é de 4 ciclos;
-
tRAS (
Active to Precharge Delay): esse parâmetro indica o intervalo, também em clocks, necessário entre um comando de ativar linha e a próxima ação do mesmo tipo. Em nosso exemplo, esse valor é de 15 ciclos de clock;
-
CR (
Command Rate): intervalo que há entre a ativação do sinal CS e qualquer outro comando. Em geral, esse valor é de 1 ou 2 ciclos de clock e é acompanhado da letra T. No nosso exemplo esse valor é de 1 ciclo.
Esses parâmetros costumam ser informados pelo fabricante em um etiqueta colada ao pente de memória (muitas vezes, o valor de CMD não é informado). Quando isso não ocorre, é possível obter essa informação através de softwares específicos (como o gratuito CPU-Z, para Windows, mostrado abaixo) ou mesmo pelo setup do BIOS.
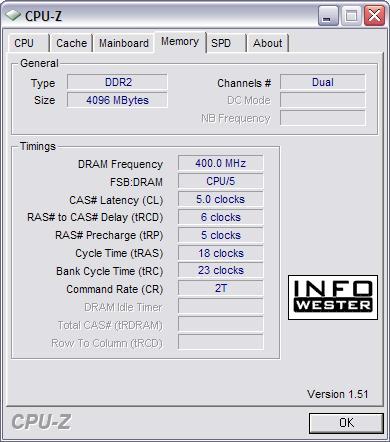 CPU-Z exibindo dados sobre memória
CPU-Z exibindo dados sobre memória
Os parâmetros de temporização fornecem uma boa noção do tempo de acesso das memórias. Note que, quando falamos disso, nos referimos ao tempo que a memória leva para fornecer os dados requisitados. O que não foi dito acima é que esse tempo é medido em nanossegundos (ns), isto é, 1 segundo dividido por 1.000.000.000.
Assim, para se ter uma noção de qual é a frequência máxima utilizada pela memória, basta dividir 1000 pelo seu tempo de acesso em nanossegundos (essa informação pode constar em uma etiqueta no módulo ou pode ser informada através de softwares especiais). Por exemplo: se um pente de memória trabalha com 15 ns, sua frequência é de 66 MHz, pois 1000/15=66.
Outros parâmetros
Algumas placas-mãe atuais ou direcionadas ao público que faz
overclock (em poucas palavras, prática onde dispositivos de hardware são ajustados para que trabalhem além das especificações de fábrica) ou, ainda, softwares que detalham as características do hardware do computador, costumam informar outros parâmetros, além dos mencionados acima. Geralmente, estes parâmetros adicionais são informados da seguinte forma: tRC-tRFC-tRRD-tWR-tWTR-tRTP (por exemplo: 22-51-3-6-3-3), também considerando ciclos de clock. Vejamos o que cada um significa:
-
tRC (
Row Cycle): consiste no tempo necessário para que se complete um ciclo de acesso a uma linha da memória;
-
tRFC (
Row Refresh Cycle): consiste no tempo necessário para a execução dos ciclos de refresh da memória;
-
tRRD (
Row To Row Delay): semelhante ao tRP, mas considera o tempo que o controlador necesita esperar após uma nova linha ter sido ativada;
-
tWR (
Write Recovery): informa o tempo necessário para que o controlador de memória comece a efetuar uma operação de escrita após realizar uma operação do mesmo tipo;
-
tWTR (
Write to Read Delay): consiste no tempo necessário para que o controlador de memória comece a executar operações de leitura após efetuar uma operação de escrita;
-
tRTP (
Read to Precharge Delay): indica o tempo necessário entre uma operação de leitura efetuada e ativação do próximo sinal.
Voltagem
Em comparação com outros itens de um computador, as memórias são um dos componentes que menos consomem energia. O interessante é que esse consumo diminuiu com a evolução da tecnologia. Por exemplo, módulos de memória DDR2 (tecnologia que ainda será abordada neste texto), em geral, exigem entre 1,8 V e 2,5 V. É possível encontrar pentes de memória DDR3 (padrão que também será abordado neste artigo) cuja exigência é de 1,5 V. Módulos de memória antigos exigiam cerca de 5 V.
Algumas pessoas com bastante conhecimento no assunto fazem overclock nas memórias aumentando sua voltagem. Com esse ajuste, quando dentro de certos limites, é possível obter níveis maiores de clock.
SPD (Serial Presence Detect)
O SPD é um pequeno chip (geralmente do tipo EEPROM) inserido nos módulos de memória que contém diversas informações sobre as especificações do dispositivo, como tipo (DDR, DDR2, etc), voltagem, temporização/latência, fabricante, número de série, etc.
 Chip SPD
Chip SPD
Muitas placas-mãe contam com um setup de BIOS que permite uma série de ajustes de configuração. Nesses casos, um usuário experimente pode definir os parâmetros da memória, no entanto, quem não quiser ter esse trabalho, pode manter a configuração padrão. Algumas vezes, essa configuração é indicada por algo relacionado ao SPD, como mostra a imagem abaixo:
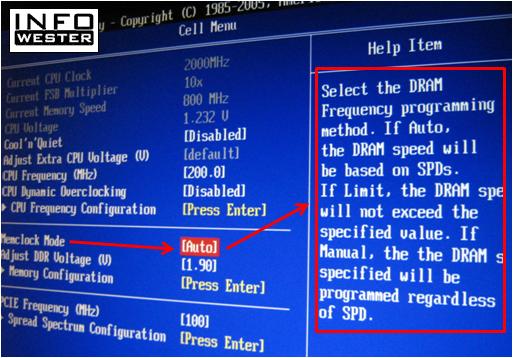 Exemplo de ajuste de memória em setup de BIOS baseado em SPD
Exemplo de ajuste de memória em setup de BIOS baseado em SPD
Detecção de erros
Alguns mecanismos foram desenvolvidos para ajudar na detecção de erros da memória, falhas essas que podem ter várias causas. Esses recursos são especialmente úteis em aplicações de alta confiabilidade, como servidores de
missão crítica, por exemplo.
Um desses mecanismos é a
paridade, capaz apenas de ajudar a detectar erros, mas não de corrigí-los. Nesse esquema, um bit é adicionado a cada byte de memória (lembre-se: 1 byte corresponde a 8 bits). Esse bit assume o valor 1 se a quantidade de bits 1 do byte for par e assume o valor 0 (zero) se a referida quantidade por ímpar (o contrário também pode acontecer: 1 para ímpar e 0 para par). Quando a leitura de dados for feita, um circuito verificará se a paridade corresponde à quantidade de bits 1 (ou 0) do byte. Se for diferente, um erro foi detectado.
A paridade, no entanto, pode não ser tão precisa, pois um erro em dois bits, por exemplo, pode fazer com que o bit de paridade corresponda à quantidade par ou ímpar de bits 1 do byte. Assim, para aplicações que exigem alta precisão dos dados, pode-se contar com memórias que tenham
ECC (
Error Checking and Correction), um mecanismo mais complexo capaz de detectar e corrigir erros de bits.
Tipos de encapsulamento de memória
O encapsulamento correspondente ao artefato que dá forma física aos chips de memória. Eis uma breve descrição dos tipos de encapsulamento mais utilizados pela indústria:
-
DIP (
Dual In-line Package): um dos primeiros tipos de encapsulamento usados em memórias, sendo especialmente popular nas épocas dos computadores XT e 286. Como possui terminais de contato - "perninhas" - de grande espessura, seu encaixe ou mesmo sua colagem através de solda em placas pode ser feita facilmente de forma manual;
 Encapsulamento DIP - Imagem por Wikipedia
Encapsulamento DIP - Imagem por Wikipedia
-
SOJ (
Small Outline J-Lead): esse encapsulamento recebe este nome porque seus terminais de contato lembram a letra 'J'. Foi bastante utilizado em módulos SIMM (vistos mais à frente) e sua forma de fixação em placas é feita através de solda, não requerendo furos na superfície do dispositivo;
 Encapsulamento SOJ
Encapsulamento SOJ
-
TSOP (
Thin Small Outline Package): tipo de encapsulamento cuja espessura é bastante reduzida em relação aos padrões citados anteriormente (cerca de 1/3 menor que o SOJ). Por conta disso, seus terminais de contato são menores, além de mais finos, diminuindo a incidência de interferência na comunicação. É um tipo aplicado em módulos de memória SDRAM e DDR (que serão abordados adiante). Há uma variação desse encapsulamento chamado
STSOP (
Shrink Thin Small Outline Package) que é ainda mais fino;
 Encapsulamento TSOP
Encapsulamento TSOP
-
CSP (
Chip Scale Package): mais recente, o encapsulamento CSP se destaca por ser "fino" e por não utilizar pinos de contato que lembram as tradicionais "perninhas". Ao invés disso, utiliza um tipo de encaixe chamado
BGA (
Ball Grid Array). Esse tipo é utilizado em módulos como DDR2 e DDR3 (que serão vistos à frente).
 Encapsulamento CSP
Encapsulamento CSP
Módulos de memória
Entendemos como
módulo ou, ainda,
pente, uma pequena placa onde são instalados os encapsulamentos de memória. Essa placa é encaixada na placa-mãe por meio de encaixes (
slots) específicos para isso. Eis uma breve descrição dos tipos mais comuns de módulos:
-
SIPP (
Single In-Line Pins Package): é um dos primeiros tipos de módulos que chegaram ao mercado. É formato por chips com encapsulamento DIP. Em geral, esses módulos eram soldados na placa-mãe;
-
SIMM (
Single In-Line Memory Module): módulos deste tipo não eram soldados, mas encaixados na placa-mãe. A primeira versão continha 30 terminais de contato (SIMM de 30 vias) e era formada por um conjunto de 8 chips (ou 9, para paridade). Com isso, podiam transferir um byte por ciclo de clock. Posteriormente surgiu uma versão com 72 pinos (SIMM de 72 vias), portanto, maior e capaz de transferir 32 bits por vez. Módulos SIMM de 30 vias podiam ser encontrados com capacidades que iam de 1 MB a 16 MB. Módulos SIMM de 72 vias, por sua vez, eram comumente encontrados com capacidades que iam de 4 MB a 64 MB;
-
DIMM (
Double In-Line Memory Module): os módulos DIMM levam esse nome por terem terminais de contatos em ambos os lados do pente. São capazes de transmitir 64 bits por vez. A primeira versão - aplicada em memória SDR SDRAM - tinha 168 pinos. Em seguida, foram lançados módulos de 184 vias, utilizados em memórias DDR, e módulos de 240 vias, utilizados em módulos DDR2 e DDR3. Existe um padrão DIMM de tamanho reduzido chamado
SODIMM (Small Outline DIMM), que são utilizados principalmente em computadores portáteis, como notebooks;
-
RIMM (
Rambus In-Line Memory Module): formado por 168 vias, esse módulo é utilizado pelas memórias Rambus, que serão abordadas ainda neste artigo. Um fato curioso é que para cada pente de memória Rambus instalado no computador é necessário instalar um módulo "vazio", de 184 vias, chamado de
C-RIMM (
Continuity-RIMM).
 Módulo de memória inserida em um slot
Módulo de memória inserida em um slot
Tecnologias de memórias
Várias tecnologias de memórias foram (e são) criadas com o passar do tempo. É graças a isso que, periodicamente, encontramos memórias mais rápidas, com maior capacidade e até memórias que exigem cada vez menos energia. Eis uma breve descrição dos principais tipos de memória RAM:
-
FPM (
Fast-Page Mode): uma das primeiras tecnologias de memória RAM. Com o FPM, a primeira leitura da memória tem um tempo de acesso maior que as leituras seguintes. Isso porque são feitos, na verdade, quatro operações de leitura seguidas, ao invés de apenas uma, em um esquema do tipo x-y-y-y, por exemplo: 3-2-2-2 ou 6-3-3-3. A primeira leitura acaba sendo mais demorada, mas as três seguintes são mais rápidas. Isso porque o controlador de memória trabalha apenas uma vez com o endereço de uma linha (RAS) e, em seguida, trabalha com uma sequência de quatro colunas (CAS), ao invés de trabalhar com um sinal de RAS e um de CAS para cada bit. Memórias FPM utilizavam módulos SIMM, tanto de 30 quanto de 72 vias;
-
EDO (
Extended Data Output): a sucessora da tecnologia FPM é a EDO, que possui como destaque a capacidade de permitir que um endereço da memória seja acessado ao mesmo tempo em que uma solicitação anterior ainda está em andamento. Esse tipo foi aplicado principalmente em módulos SIMM, mas também chegou a ser encontrado em módulos DIMM de 168 vias. Houve também uma tecnologia semelhante, chamada
BEDO (
Burst EDO), que trabalhava mais rapidamente por ter tempo de acesso menor, mas quase não foi utilizada, pois tinha custo maior por ser de propriedade da empresa Micron. Além disso, foi "ofuscada" pela chegada da tecnologia SDRAM;
 Módulo de memória EDO
Módulo de memória EDO
-
SDRAM (
Synchronous Dynamic Random Access Memory): as memórias FPM e EDO são assíncronas, o que significa que não trabalham de forma sincronizada com o processador. O problema é que, com
processadores cada vez mais rápidos, isso começou a se tornar um problema, pois muitas vezes o processador tinha que esperar demais para ter acesso aos dados da memória. As memórias SDRAM, por sua vez, trabalham de forma sincronizada com o processador, evitando os problemas de atraso. A partir dessa tecnologia, passou-se a considerar a frequência com a qual a memória trabalha para medida de velocidade. Surgiam então as memórias
SDR SDRAM (
Single Data Rate SDRAM), que podiam trabalhar com 66 MHz, 100 MHz e 133 MHz (também chamadas de PC66, PC100 e PC133, respectivamente). Muitas pessoas se referem a essa memória apenas como "memórias SDRAM" ou, ainda, como "memórias DIMM", por causa de seu módulo. No entanto, a denominação SDR é a mais adequada;
 Módulo de memória SDR SDRAM -
Módulo de memória SDR SDRAM -
Observe que neste tipo há duas divisões entre os terminais de contato
-
DDR SDRAM (Double Data Rate SDRAM): as memórias DDR apresentam evolução significativa em relação ao padrão SDR, isso porque elas são capazes de lidar com o dobro de dados em cada ciclo de clock (memórias SDR trabalham apenas com uma operação por ciclo). Assim, uma memória DDR que trabalha à frequência de 100 MHz, por exemplo, acaba dobrando seu desempenho, como se trabalhasse à taxa de 200 MHz. Visualmente, é possível identificá-las facilmente em relação aos módulos SDR, porque este último contém duas divisões na parte inferior, onde estão seus contatos, enquanto que as memórias DDR2 possuem apenas uma divisão. Você pode saber mais sobre essa tecnologia na matéria
Memória DDR, publicada aqui no InfoWester;
- DDR2 SDRAM: como o nome indica, as memórias DDR2 são uma evolução das memórias DDR. Sua principal característica é a capacidade de trabalhar com quatro operações por ciclo de clock, portanto, o dobro do padrão anterior. Os módulos DDR2 também contam com apenas uma divisão em sua parte inferior, no entanto, essa abertura é um pouco mais deslocada para o lado. Saiba mais sobre essa tecnologia na matéria
Memória DDR2, disponibilizada aqui no InfoWester;
 Memória DDR2 acima e DDR abaixo -
Memória DDR2 acima e DDR abaixo -
Note que a posição da divisão entre os terminais de contato é diferente
- DDR3 SDRAM: as memórias DDR3 são, obviamente, uma evolução das memórias DDR2. Novamente, aqui dobra-se a quantidade de operações por ciclo de clock, desta vez, de oito. Na época de fechamento deste artigo, as memórias DDR3 ainda não eram muito populares. Saiba mais sobre essa tecnologia
nesta matéria da Wikipedia;
-
Rambus (
Rambus DRAM): as memórias Rambus recebem esse nome por serem uma criação da empresa Rambus Inc. e chegaram ao mercado com o apoio da
Intel. Elas são diferentes do padrão SDRAM, pois trabalham apenas com 16 bits por vez. Em compensação, memórias Rambus trabalham com frequência de 400 MHz e com duas operações por ciclo de clock. Tinham como desvantagens, no entanto, taxas de latência muito altas, aquecimento elevado e maior custo. Memórias Rambus nunca tiveram grande aceitação no mercado, mas também não foram um total fiasco: foram utilizadas, por exemplo, no console de jogos Nintendo 64. Curiosamente, as memórias Rambus trabalham em pares com "módulos vazios" ou "pentes cegos". Isso significa que, para cada módulo Rambus instalado, um "módulo vazio" tem que ser instalado em outro slot. Essa tecnologia acabou perdendo espaço para as memórias DDR.
Finalizando
Com o passar do tempo, a evolução das tecnologias de memórias não somente as torna mais rápidas, mas também faz com que passem a contar com maior capacidade de armazenamento de dados. Memórias ROM do tipo Flash, por exemplo, podem armazenar vários gigabytes. No que se refere às memórias RAM, o mesmo ocorre. Por conta disso, a pergunta natural é: quanto utilizar? A resposta depende de uma série de fatores, no entanto, a indústria não para de trabalhar para aumentar ainda mais a velocidade e a capacidade desses dispositivos. Portanto, não se espante: quando menos você esperar, vai ouvir falar de uma
nova tecnologia de memória que poderá se tornar um novo padrão de mercado :)
 O americano Shawn Fanning, desenvolveu um software que permitia aos internautas compartilharem MP3 pela internet: o Napster. O programa tornou muito fácil a tarefa de encontrar e baixar MP3 pela rede, pois possibilitou a formação de um enorme acervo de música digital. Isso porque o Napster usava um método totalmente diferente. Não armazenava nada em seus servidores, apenas um índice, que era necessário para a busca de canções. Uma vez que alguém tenha encontrado a música desejada, o download passava a ser feito a partir dos computadores de usuários do serviço que tenham a música armazenada em seu PC. Ou seja, cada computador cadastrado no serviço era ao mesmo tempo cliente e servidor.
O americano Shawn Fanning, desenvolveu um software que permitia aos internautas compartilharem MP3 pela internet: o Napster. O programa tornou muito fácil a tarefa de encontrar e baixar MP3 pela rede, pois possibilitou a formação de um enorme acervo de música digital. Isso porque o Napster usava um método totalmente diferente. Não armazenava nada em seus servidores, apenas um índice, que era necessário para a busca de canções. Uma vez que alguém tenha encontrado a música desejada, o download passava a ser feito a partir dos computadores de usuários do serviço que tenham a música armazenada em seu PC. Ou seja, cada computador cadastrado no serviço era ao mesmo tempo cliente e servidor.  Há vários programas bons para executar MP3, tanto para gravar, ouvir, ou fazer seu álbum no computador. Um dos mais usados, é o Winamp, que possui versões gratuitas e pode ser baixado em www.winamp.com. O programa é compatível com vários formatos e tem vários recursos. Um deles é a possibilidade de colocar skins ou peles (efeitos visuais no programa), que podem ser baixado em vários sites. O programa é leve e bastante intuitivo. Possui um gerenciador de listas de MP3 muito prático e que facilita a organização e a execução de faixas.
Há vários programas bons para executar MP3, tanto para gravar, ouvir, ou fazer seu álbum no computador. Um dos mais usados, é o Winamp, que possui versões gratuitas e pode ser baixado em www.winamp.com. O programa é compatível com vários formatos e tem vários recursos. Um deles é a possibilidade de colocar skins ou peles (efeitos visuais no programa), que podem ser baixado em vários sites. O programa é leve e bastante intuitivo. Possui um gerenciador de listas de MP3 muito prático e que facilita a organização e a execução de faixas.